


This is the point at which we depart from the lexical conception of
collocations. In much the same way that the approach described above treats a
text as a collection of words separated by sentence boundaries, we treat a
training set of documents as just such a collection of bounded subparts
between which important relationships or associations can be identified. For
this, we follow a two step process of contingency table construction and
association weight calculation. During training, we treat each Document
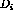 as a multi-set
as a multi-set
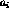 of
m lexical clues and
of
m lexical clues and 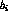 of n authorized subject headings:
of n authorized subject headings: 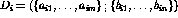 . In this view, the associations contained in a particular
document
. In this view, the associations contained in a particular
document 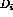 consists of all the ordered pairs that can be formed from
consists of all the ordered pairs that can be formed from
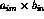 document subparts. As each of the pairs for each
document is considered, contingency tables are constructed and updated.
Finally, when all the pairs and contingency tables have been recorded, the
strength of the associations are calculated and recorded along with pairs and
their contingency tables.
document subparts. As each of the pairs for each
document is considered, contingency tables are constructed and updated.
Finally, when all the pairs and contingency tables have been recorded, the
strength of the associations are calculated and recorded along with pairs and
their contingency tables.
For example, during training, a document with a title ``Biomedical resources
on Usenet'' to which the subjects ``Information services'',
``Internetworking'' and ``Medical computing'' have been assigned is treated as
nine contingency tables (associations). That is, 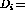 ({biomedical,
resources, usenet}; {information-services, internetworking,
medical-computing}) and the
({biomedical,
resources, usenet}; {information-services, internetworking,
medical-computing}) and the 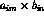 associations consisting of
each of the possible pairings are
recorded and the contingency tables are updated. Every contingency table in
the dictionary is affected by every new association that is added. Each of
the existing contingency tables either matches the association being
processed, in which case the AB field is incremented as a positive
observation; matches only the lexical clue of the current pair, in which case
associations consisting of
each of the possible pairings are
recorded and the contingency tables are updated. Every contingency table in
the dictionary is affected by every new association that is added. Each of
the existing contingency tables either matches the association being
processed, in which case the AB field is incremented as a positive
observation; matches only the lexical clue of the current pair, in which case
 is incremented; matches only the term, in which case
is incremented; matches only the term, in which case 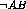 is
incremented; or is a complete mismatch, in which case
is
incremented; or is a complete mismatch, in which case 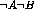 is
incremented.
is
incremented.
Finally, after all of the associations in the whole document collection have been read and recorded, the weights can be calculated from the observed values in the contingency tables as described above in Section 2.2.
For each pair in the collection of documents at hand, we now have three useful
pieces of information -- the word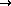 subject heading pair, the
contingency table for that pair, and its calculated strength of association --
which we use to create a ``dictionary'' of collocations. Of particular
interest in the dictionaries is their not surprising dependence on the
training data. In the example in Figure 1, several of the
collocations of the document term ``copyright'' are shown. From these
entries, taken from a dictionary mapping individual title words to subjects,
we can quickly get a good idea of the various contexts in which ``copyright''
appears in this particular sample collection (see
Section 4.1 below).
subject heading pair, the
contingency table for that pair, and its calculated strength of association --
which we use to create a ``dictionary'' of collocations. Of particular
interest in the dictionaries is their not surprising dependence on the
training data. In the example in Figure 1, several of the
collocations of the document term ``copyright'' are shown. From these
entries, taken from a dictionary mapping individual title words to subjects,
we can quickly get a good idea of the various contexts in which ``copyright''
appears in this particular sample collection (see
Section 4.1 below).
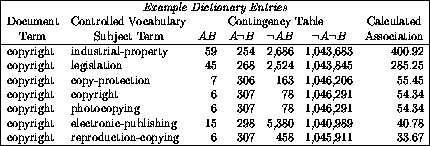
Figure 1: Several typical entries from a collocation
dictionary trained with titles, authors and abstracts. Each entry consists
respectively of a term found in the document, an authorized subject heading,
the contingency table for the pair, and the calculated weight of association.
This example also illustrates the ``rare'' nature of the words in text,
especially in titles. In the 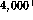 articles, containing just over
1,000,000 words, used for training in this experiment the word ``copyright''
only appears 313 times in 66 pairs, 37 of which appear only once.
articles, containing just over
1,000,000 words, used for training in this experiment the word ``copyright''
only appears 313 times in 66 pairs, 37 of which appear only once.
In the second stage of this algorithm, we use the dictionary of associations created during training to predict which of the controlled subject headings best match a given set of lexical clues from the same language subdomain.
For each document in a given collection (test set), we extract the individual lexical clues (in this case, words) from the bibliographic representation. Each word in the dictionary is looked up and all of the dictionary entries associated with the particular word (or clue) at hand are retrieved. At this stage, each document now has associated with it a list of dictionary entries which can be used for ranking the subject headings in them. Note that though the entries are unique, consisting of document terms, subject headings, contingency tables and calculated weights, the subject headings in them need not be. Each document term can be associated with any number of subject headings.
The next step is to collapse these entries into unique subject headings and
weights. We transform each of our documents into a vector of weights: 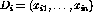 where each weight
where each weight 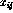 is computed from the
dictionary entries that associate a lexical clue from document i with a
subject heading j. For example, if a catalog record contains the word
``copyright'' and ``software'', and both are associated with the subject
heading ``copy-protection'' with the weights 8.72 and 3.22 respectively, we
simply combine these weights by adding them together with the result that the
subject heading ``copy-protection'' has the weight 11.94. This is not the
only way to combine weights. It tends to emphasize the most commonly assigned
subject headings, but then, as the distribution of subject headings in online
catalogs indicates, this is also the way human catalogers perform.
is computed from the
dictionary entries that associate a lexical clue from document i with a
subject heading j. For example, if a catalog record contains the word
``copyright'' and ``software'', and both are associated with the subject
heading ``copy-protection'' with the weights 8.72 and 3.22 respectively, we
simply combine these weights by adding them together with the result that the
subject heading ``copy-protection'' has the weight 11.94. This is not the
only way to combine weights. It tends to emphasize the most commonly assigned
subject headings, but then, as the distribution of subject headings in online
catalogs indicates, this is also the way human catalogers perform.
We now have each document associated with a list of subject headings and weights. Depending on the cataloging policy of the training set (i.e. how many subject headings are normally assigned to any individual document), some number of subject headings can be selected off the top of the list as the most likely subject headings for each document.
For the purposes of evaluation, we use this algorithm for assigning subject
headings to actual document titles and abstracts; but it could as easily be
used for determining helpful (because likely) subject headings to be searched
from a natural language query statement. As an example, consider a query such
as ``subject access in online library catalogs''. For this query, the system
retrieves ``library automation'', ``cataloguing'', ``bibliographic systems'',
``information services'', ``indexing'', ``libraries'', ``information
retrieval'', ``vocabulary'', ``natural languages'', and ``information
retrieval systems'' as the most highly associated authorized subject headings
in the author and title dictionary described on page  below.
below.