


The test collection used in these experiments was drawn from the 1,438,346
citations in the INSPEC citation database . This dataset is produced and
indexed by the Information Division of the Institution of Electrical Engineers
(IEE) from over 4,000 journals and other publications in physics, electronics,
and computing from 1988 to the present. Journals account for approximately
78% of the citations in INSPEC, the remainder being conference proceedings,
books, reports, and dissertations in the covered fields. Most citations
include abstracts. The INSPEC thesaurus, from which the controlled vocabulary
subject headings in our experiment were drawn, consists of approximately 6,500
``preferred terms'', i.e. terms used in indexing, and about 7,200 ``lead-in''
terms or cross-references [IEE1993].
. This dataset is produced and
indexed by the Information Division of the Institution of Electrical Engineers
(IEE) from over 4,000 journals and other publications in physics, electronics,
and computing from 1988 to the present. Journals account for approximately
78% of the citations in INSPEC, the remainder being conference proceedings,
books, reports, and dissertations in the covered fields. Most citations
include abstracts. The INSPEC thesaurus, from which the controlled vocabulary
subject headings in our experiment were drawn, consists of approximately 6,500
``preferred terms'', i.e. terms used in indexing, and about 7,200 ``lead-in''
terms or cross-references [IEE1993].
Following Sievert & Andrews (1991) we created our test collection by sampling this database by journal title. This process of selection is simple, guarantees a usable sample, avoids the influence of potential indexer inconsistency, and does not use any of the fields used for testing later. To keep our sample within a reasonable and familiar language subdomain and to a manageable size, we drew our sample from journals with titles containing the words ``libraries'', ``library'', ``information science'', ``linguistics'', or ``sigir''. This selection provided us with a test collection of 4,626 tagged citations from 58 journals. In order to train our dictionaries, we randomly selected and removed 10% of these citations for later use as a test set, and used the remaining 90% for training. This follows standard practice for this approach in computational linguistics.
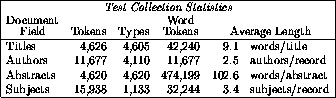
Figure 2: Summary of statistics for the test collection,
including author, title, subject and abstract counts. A full author
name is counted as one word.

Figure 3: A typical sample test document from the test
collection used in this experiment.
We evaluated the performance of these algorithms by comparing them to the performance of human indexers on the same task. The ``test'' documents, as described above, are a subset of the catalog records from the original dataset.
We offer a small group of measurements for this comparison. For each test document we gathered observations for a commonly used indexer consistency measure, and for the common information retrieval measures of precision and recall.
In a retrieval situation, the standard formulation of these measures is that
precision is the ratio of the number of relevant retrieved documents to all
the retrieved documents, and that recall is the ratio of the number of
relevant retrieved documents to the number of all relevant documents,
retrieved or not. Let Relevant be the set of all relevant documents in a
collection and Retrieved be the set of all documents retrieved by the system
during a particular use, then:
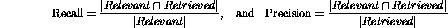
where ``|x|'' is the number of members in a set.
Based on the lexical clues contained in a test document (some combination of
words or phrases from the title, authors and abstract), the system retrieves
some number of the ``most likely'' controlled vocabulary subject headings
which are then compared to the subject headings actually assigned by a human
indexer. This comparison is used to determine our algorithm's accuracy
measured in terms of precision and recall.