


The experiments described here are designed to test the effectiveness of various combinations of data fields used for training and automatic indexing. Typically, online collections of documents such as technical reports have only authors, titles and abstracts available for searching or automatic indexing. For this reason we explore here a series of word based experiments using these fields.
In the training phase, we built three dictionaries of association based on the
individual words in the various fields using the 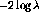 statistic
described above on (1) titles; (2) titles and authors; and (3) titles,
authors and abstracts.
statistic
described above on (1) titles; (2) titles and authors; and (3) titles,
authors and abstracts.
In the testing phase, a similar procedure was followed. We submitted words from the author, title and abstract fields for documents held out of the training to the system, and compared the retrieved subject headings to the subject headings that actually had been assigned to each document. For each of the three dictionaries, we ran four separate sets of query tests: (1) title words; (2) author and title words; (3) title and abstract words; and finally, (4) author, title and abstract words.
We report the measures described above at several levels of exhaustive indexing (``depths'') for each experiment.
In the first experiment, we tested the effectiveness of a dictionary trained only with titles. This dictionary has 56,321 entries with 5,033 unique words and 1,083 subjects (leaving 50 subjects which appear in the full collection with no training data in these experiments).
The results of querying against this title dictionary are summarized in Table 1. Each row of this table contains the following information. The first column contains the fields used in the queries for retrieval. We first queried with words from just the titles, then titles and abstracts. The next column contains the number of controlled vocabulary subject headings retrieved. Since the number of subject headings assigned to any item is primarily a matter of cataloging agency policy, we tested a range of depths. In the next column we report the average number of ``matches'' or subject heading assignments which match the actual human cataloging for the test set. We give the indexer consistency measure in the next column, followed by precision and recall results.
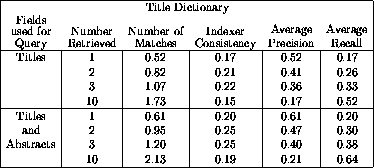
Table 1: Summary of test results against a dictionary trained
with titles only. The number of subject headings retrieved (depth); number
of matches (the average number of subject headings in common between human
and automatic assignments -- the average number of human assigned subject
headings was 3.5). Indexer consistency, average precision and average
recall are the statistical measures described above.
These results show that using only titles for training and retrieval, the first subject is right in just over half of the cases. At the depth of retrieval increases, recall goes up and precision goes down, as expected. Indexer consistency follows a characteristic pattern of peaking when the retrieval depth is close to the average number of actual assignments (3.5 subject headings). Since this measure depends in part on catalogers assigning the same number of subject headings, this makes perfect sense. In this case, at a depth of three subject heading assignments, indexer consistency of 0.22 compares favorably with Chan's observed indexer consistency of 0.21 exact LCSH matches.
Querying with titles and abstracts improves performance noticeably for all of the comparisons. Slightly over 60% of the first subject heading assignments now match, and indexer consistency reaches 0.25 at a depth of three.
The contrast between querying with titles and with authors, titles and abstracts for precision and recall can clearly be seen in Figure 4. In this figure, we plot precision and recall for all 10 retrieval depths which show reasonable improvement throughout. Figure 5 shows the consistent improvement in indexer consistency for these same two query sets.
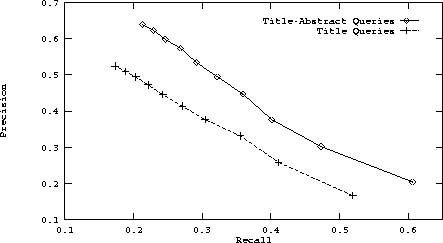
Figure 4: A plot of precision against recall for the title
trained dictionary.
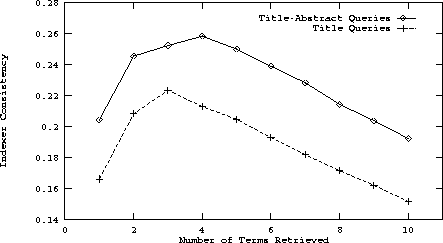
Figure 5: A plot of indexer consistency for the title trained
dictionary.
For the second set of tests, we trained a dictionary using both titles and authors. This dictionary contained 8,732 words mapped onto the same 1,083 subjects in a total of 83,951 entries, a gain of 3,699 ``words'' (i.e. authors) in the training set and 27,630 associations in the dictionary.
As Figures 6 and 7 indicate, precision, recall and indexer consistency improved considerably when authors, titles and abstracts were used for queries in contrast to when titles only were used. The results of each of the query sets for this dictionary are summarized in Table 2. When queried with the titles only, this author-title dictionary performed almost exactly the same as the title dictionary, with indexer consistency peaking at 0.23 at a depth of three subject headings. Interestingly, at a depth of two, the average number of matches dropped slightly from 0.82 to 0.81.
The second part of the table shows that adding the authors to the queries hurt performance slightly for all measures presented. Querying with titles and abstracts produced mixed results once again, but nonetheless achieved a high indexer consistency of 0.25, which is already better than any score from the previous title dictionary.
The fourth section of Table 2 contains the peak indexer
consistency measure for all the dictionaries and, except for at a depth of three subject headings, it equals or betters the
title dictionary in all measures.
and, except for at a depth of three subject headings, it equals or betters the
title dictionary in all measures.
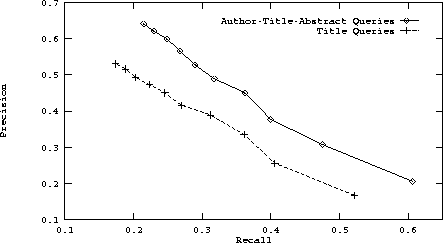
Figure 6: A plot of retrieval effectiveness for the
author-title trained dictionary using (1) author-title-abstract
queries and (2) title queries for retrieval.
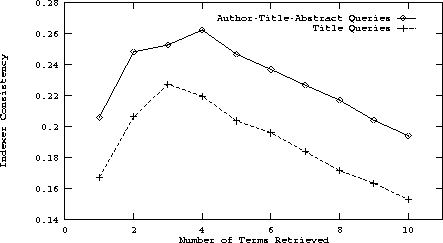
Figure 7: A plot of indexer consistency for the author-title
trained dictionary using (1) author-title-abstract queries and (2) title
queries for retrieval.
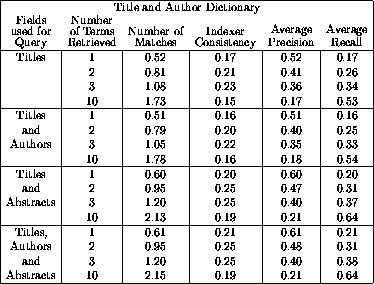
Table 2: Summary of test results against the dictionary trained
with titles and authors. The number of subject headings retrieved (depth);
number of matches (the average number of subject headings in common between
human and automatic assignments -- the average number of human assigned
subject headings was 3.5). Indexer consistency, average precision and
average recall are the statistical measures described above.
The third test dictionary was trained using authors, titles and abstracts. This dictionary consisted of the same 1,083 subjects with mappings from 19,677 distinct words in 375,143 entries. Compared to the author-title dictionary, there were nearly four times as many distinct words used in training, and nearly seven times as many associations, leading to much broader vocabulary coverage.
The results of this test are summarized in Table 3. Despite
the broader vocabulary coverage, there was no advantage gained by including
the words from abstracts in the training phase. Adding abstracts to the
queries improved all measures substantially, which can be seen very clearly
for precision and recall in Figure 8 and for indexer
consistency in Figure 9 for the title and
author-title-abstract queries. The effect of adding authors to queries is
both slight and mixed. The differences in performance the title-abstract
queries and the author-title-abstract queries at all depths and in all
measures are too slight to be considered significant. The title and
author-title queries performed similarly, with author-title queries doing
slightly better with 0.52 precision at a depth of one. The
author-title-abstract queries and title-abstract queries both achieved an
indexer consistency of 0.26 at a depth of four, matching the indexer consistency of 0.26 from the
previous author-title dictionary.
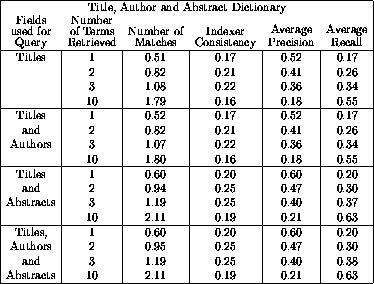
Table 3: Summary of test results against the dictionary
trained with titles, authors and abstracts. The number of subject headings
retrieved (depth); number of matches (the average number of subject headings
in common between human and automatic assignments -- the average number of
human assigned subject headings was 3.5). Indexer consistency, average
precision and average recall are the statistical measures described above.
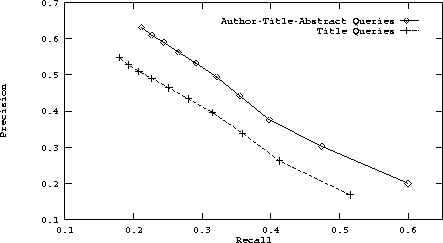
Figure 8: A plot of the improvement of retrieval
effectiveness for the author-title-abstract trained dictionary using
(1) author-title-abstract queries and (2) title queries for retrieval.
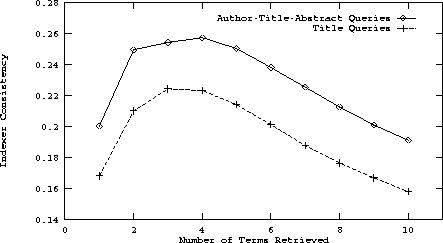
Figure 9: A plot of the improvement of indexer
consistency for the author-title-abstract trained dictionary using
(1) author-title-abstract queries and (2) title queries for retrieval.
As a test of the effectiveness of the 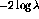 statistic, we trained a
second version of the title dictionary using the
statistic, we trained a
second version of the title dictionary using the 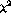 statistic in order
to compare their performance. Table 4 compares the performance of
these association measures on the title dictionary using the
author-title-abstract queries for retrieval. As the table indicates, the
statistic in order
to compare their performance. Table 4 compares the performance of
these association measures on the title dictionary using the
author-title-abstract queries for retrieval. As the table indicates, the
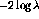 performs far better in every measure given here. In
particular, the respectable indexer consistency score of 0.25 at a depth of 3
for
performs far better in every measure given here. In
particular, the respectable indexer consistency score of 0.25 at a depth of 3
for 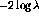 drops to 0.16 for the
drops to 0.16 for the 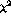 statistic, well below the
0.21 reported by Chan for exact LCSH matches. The results are also graphed in
Figures 10 and 11.
statistic, well below the
0.21 reported by Chan for exact LCSH matches. The results are also graphed in
Figures 10 and 11.
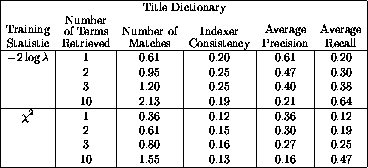
Table 4: Summary of test results against the dictionary
trained only with titles, but using titles, authors and abstracts for
querying. The training statistics are the 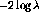 statistic described
above and
statistic described
above and 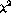 statistic.
statistic.
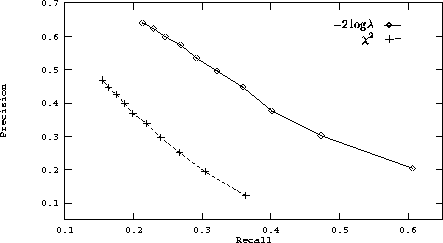
Figure 10: A graph of the improvement of precision and recall for
the title dictionary against author-title-abstract queries comparing the
performance of the 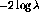 and
and 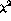 statistics.
statistics.
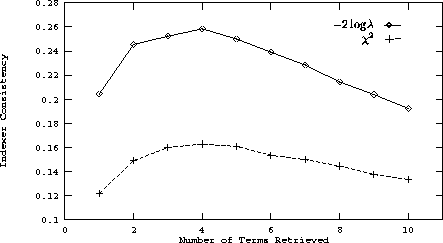
Figure 11: A graph of the improvement of indexer consistency for
the title dictionary against author-title-abstract queries comparing the
performance of the 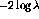 and
and 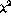 statistics.
statistics.