


In addition to the tests reported above, for completeness, we also ran the same experiments using a dictionary trained with titles and abstracts and found that it performed just slightly worse than the larger author-title-abstract dictionary.
The indexer consistency measure showed a consistent pattern with regard to precision and recall. In every case, indexer consistency peaked at or near the point where precision and recall cross when plotted against depth of retrieval. This characteristic pattern is illustrated in Figure 12 for the author-title-abstract queries being run against the author-title dictionary.
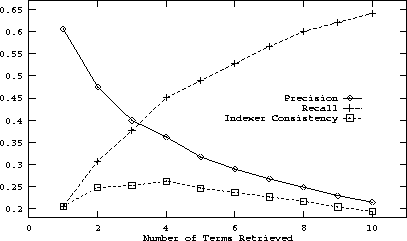
Figure 12: A graph of precision, recall and indexer consistency for
the author-title dictionary against author-title-abstract queries. Note
that indexer consistency characteristically peaks at the point where precision
and recall cross when plotted against depth of retrieval.
Adding authors to both the training and retrieval phases, especially in conjunction with adding abstracts to the queries, had a better effect than expected, with the somewhat surprising result that we achieved the best performance, in terms of the indexer consistency measure, with the author-title dictionary being queried with authors, titles and abstracts.
Adding abstracts to the training phase had less effect than expected, though it did tend to improve retrieval marginally.
The results of the experiments above show that an automatic algorithm for assigning controlled vocabulary subject headings within an identifiable language subdomain can approximate observed human performance in terms of indexer consistency.
Further, we believe that our observations are rather conservative, and subject to substantial improvement. Even where the subject headings chosen by the algorithm do not agree exactly with the subject headings assigned by a human indexer, they are often found to match broader and narrower subject headings in the thesaurus hierarchy for the actual subject headings assigned by human indexers. In effect, we are working against cataloging agency policy. In this case, the most common practice is to follow the lead of the Library of Congress and assign the most specific subject heading available. Such a policy leads to cases where for example ``information retrieval'' and ``information retrieval systems'' may both reasonably describe the content of the document, but only the latter more specific subject heading can be assigned. If our algorithm assigns both, the former will be judged incorrect. This is further compounded by policies which limit the number of subject headings which can be assigned to a document. In the present test collection, where only three or four subject headings can be assigned, this leads to problems when a document is actually about more topics. In both of these cases, given knowledge of the controlled vocabulary hierarchy, cataloging policy and appropriate inference methods, we expect to see improvements in the performance of this basic approach.
We believe that this algorithm can be used to good effect in many situations where human cataloging is, for reasons of cost or time, impossible or impractical, as well as serving as an aid to human cataloging. We also believe that it is not a complete substitute for such human cataloging. Further, such automatic subject categorization should be very useful in information retrieval systems where either there is no subject cataloging or where there is some sort of vocabulary dissonance (e.g. the mismatched author or indexer vocabularies encountered when exploring a new or unfamiliar literature).