We report here on a two stage algorithm which, based on lexical clues contained in a document representation, assigns to that document subject headings from a controlled vocabulary.
The algorithm exploits the knowledge implicitly stored in a catalog record to
which subject headings have been assigned by a human cataloger. By studying
closely the associations between the lexical clues found in the
records![]() and the assigned indexing (subject headings) of a large set of
human-indexed catalog records, we train our algorithm to predict which subject
headings have a high likelihood of being associated with new titles (and
abstracts) when they are presented to an automated system. Such an approach
is not conceptually without precedent [Maron & Kuhns1960,Maron1961,Kar & White1978], but the
computational resources and statistical methods have limited the size and
effectiveness of such research. For the current research, we implement this
scheme using the authors, titles, abstracts and controlled vocabulary subject
headings in 4,626 catalog records from the INSPEC database on the University
of California's MELVYL online catalog.
and the assigned indexing (subject headings) of a large set of
human-indexed catalog records, we train our algorithm to predict which subject
headings have a high likelihood of being associated with new titles (and
abstracts) when they are presented to an automated system. Such an approach
is not conceptually without precedent [Maron & Kuhns1960,Maron1961,Kar & White1978], but the
computational resources and statistical methods have limited the size and
effectiveness of such research. For the current research, we implement this
scheme using the authors, titles, abstracts and controlled vocabulary subject
headings in 4,626 catalog records from the INSPEC database on the University
of California's MELVYL online catalog.
In order to ``learn'' the associations, we explore a ``collocation'' technique
borrowed from computational linguistics. The training phase identifies and
extracts content-bearing lexical items from elements found in bibliographic
records (authors, titles, subjects, abstracts) and ``collocates'' (associates)
them with manually-assigned subject headings (controlled vocabulary index
terms). We take a broad view of ``collocation'' here, by which we mean there
is some measurable association or mapping between the extracted
lexical units and the assigned indexing terms![]() . From this mapping,
we create a ``dictionary'' of associations which is used in the deployment
phase. For example, when a new document is presented to the system,
associations for each lexical unit are looked up in the dictionary, ranked,
and then used to predict the most probable subject heading assignments for
that document.
. From this mapping,
we create a ``dictionary'' of associations which is used in the deployment
phase. For example, when a new document is presented to the system,
associations for each lexical unit are looked up in the dictionary, ranked,
and then used to predict the most probable subject heading assignments for
that document.
In effect, this is an attempt to use lexical context, in the form of co-occurring terms and subject headings, to do topic (or subject) tagging without complete semantic analysis.
A common approach to subject access is to organize collections by topic.
Searches of these collections may be effected directly, for example by
browsing the items themselves. When collections become too large to be
browsed directly or are located at some physical (or
temporal![]() ) distance from the searcher, they may be searched indirectly
via a collection of derived surrogates or representations. Typically, such
collections of surrogates are gathered into catalogs based on subject schemes.
The primary purpose of library catalogs, electronic and otherwise, is ``[to]
show what a library has ... on a given subject'' [Cutter1904].
) distance from the searcher, they may be searched indirectly
via a collection of derived surrogates or representations. Typically, such
collections of surrogates are gathered into catalogs based on subject schemes.
The primary purpose of library catalogs, electronic and otherwise, is ``[to]
show what a library has ... on a given subject'' [Cutter1904].
However, the models of library acquisition, cataloging and reference services that have supported such broad based subject access are not currently being applied in today's exploding online network environment. There are many reasons for this, for example ignorance outside the library community of such support mechanisms, but also the simple matter of cost. Abstracting and indexing vendors, such as INSPEC and Dialog, which cover many of the traditional print journals, might expand to cover electronically published journals, but only if and when it becomes economically feasible. And what about non-commercial or non-profit documents? Though subject cataloging is not without its problems [Larson1991], association based automatic indexing would provide an enormous cost effective improvement over the limitations of the full-text boolean ``keyword'' search environment [Blair & Maron1985,Blair & Maron1990] which currently dominates network information services.
Human indexing of network resources, prohibited by overwhelming time and cost factors, is unrealistic. Simple word frequency applications to classification do not attempt to account for the historical evidence provided by associations between document terms and subject headings to predict highly likely subject access points.
One way to measure the quality of automatically generated subject indexing is to compare it to that of human subject indexing. This can be done by comparing the subject headings assigned by the automatic method with those that have been assigned by humans, though concerns have been raised regarding how to interpret such a comparison [Soergel1975]. A major source of this concern is the level of consistency to be expected between the automated and human indexing.
In the context of human indexing, the function of the indexer is to assign some number of authorized subject headings to each document as it enters the system. The number of subject headings assigned is normally a matter of policy driven by cost. The subject headings are meant to be those that best capture the content of the document. Indexer consistency is the extent to which different indexers (or the same indexer at different times) will choose the same subject headings for the same documents. The question then is one of how to measure indexer consistency, and given that measure, how to interpret it.
Past work on inter-indexer consistency has been motivated by the perception that high levels of consistency should improve information retrieval effectiveness. Though Leonard's work supports this view [Leonard1977], it is not universally accepted [Cooper1969,Soergel1994]. It has been argued that consistency is not always desirable, for example in the case of consistently bad indexing. Cooper concluded that ``indexing consistency cannot safely be used as a gauge of indexing quality''.
Chan compared the Library of Congress Subject Headings (LCSH) assigned by the Library of Congress (LC) with non-LC cataloging [Chan1989]. She reported that out of a sample of 100 pairs of records, 15 match exactly, 80 partially, and 5 not at all. Interestingly, of the 15 perfect matches, 6 were considered ``matches'' because no subjects were assigned at all, leaving only 9 cases where all of the subjects actually assigned matched. Perfectly matched records were those which match in both number of headings assigned and in the content of those headings. Unmatched records were those which have nothing in common. Partial matches contained ``one or more ... identical words in the main heading'', which included all of the remaining records.
Sievert and Andrews found a 48% match between authorized index terms
(descriptors) in 71 pairs of duplicate records found in Information Science
Abstracts (ISA) [Sievert & Andrews1991]. Their descriptors consisted of one main
heading and one or two subheadings drawn from a controlled
vocabulary![]() . Their consistency percentage measure was calculated
as
. Their consistency percentage measure was calculated
as

where M and N are the numbers of unique terms assigned by cataloger 1 and 2, respectively, A the number of terms in common to both indexers, and 100 a scaling factor (so the scores will fall between 0 and 100 percent).
This measure can also be written as![]() :
:

Soergel gives this measure of consistency, and others, including measure for completeness, purity and impurity, in [Soergel1994]. He also points out that high indexing correctness results in high consistency, but, as mentioned above, high consistency, though a necessary condition for high correctness, is not a sufficient condition for high indexing correctness.
Interestingly, this measure can be used to compare directly Chan's and
Sievert's results by taking Sievert's percentage as a decimal fraction as the
Indexer Consistancy measure does. Chan reports that she found 70 exact
matches of subjects assigned out of 334 total unique assignments (404 total
assignments less the 70 in common) by either cataloging agency for an indexer
consistency of 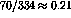 . Further, due to the convoluted nature
of LCSH subheadings, she reports that only 53 of 190 total possible matches
are complete mismatches, which means that for complete and partial matches,
indexer consistency
. Further, due to the convoluted nature
of LCSH subheadings, she reports that only 53 of 190 total possible matches
are complete mismatches, which means that for complete and partial matches,
indexer consistency 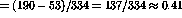 . Both of these
numbers are below the 0.48 reported by Sievert, but compare well with our
results reported below.
. Both of these
numbers are below the 0.48 reported by Sievert, but compare well with our
results reported below.
Though these indexing consistency studies are not large enough to allow one to draw any hard and fast conclusions, they are suggestive in their results and together, they give us a general idea of the sort of consistency that might be expected between indexers. We will report the indexer consistency measure along with our own measure in the experiments below.