Paper for International Society for Knowledge Organization, ISKO6, Toronto, July 2000.
Michael K. Buckland, Aitao Chen, Michael Gebbie, Youngin Kim, & Barbara Norgard.
School of Information Management & Systems, University of California, Berkeley, USA
Variation by Subdomain in Indexes to Knowledge Organization Systems
Abstract: Bibliographies and their knowledge organization systems commonly cover broad topical areas. Indexes to knowledge organization systems, such as the Subject Index to the Dewey Decimal Classification, provide a general index to the entirety. However, every community and every specialty develops its own specialized vocabulary. An index derived from the specialized use of language within a single subdomain could well be different from a general-purpose index for all domains and preferable for that subdomain. Statistical association techniques can be used to create indexes to knowledge systems. A preliminary analysis based on the INSPEC database shows that subdomain indexes differ significantly from each other and from a general index. The greater the polysemy of individual words the greater difference in the indexes.
1. Indexes to Knowledge Organization Systems
The Subject Index (or "Relativ Index") to Dewey's Decimal Classification is an obvious example of an index to a knowledge organization system. Library users could not be expected to know what numbers in the classification scheme stood for any given topic, so the Subject Index provided a map from words and phrases in English to the corresponding numbers, in the following form: "If you are interested in [noun], look for this [number]." Dewey himself considered that the index was of great importance because it would lead the user from the right topic (in their own words) to the right number in the classified arrangement. We refer to such indexes as "entry vocabulary" indexes, because they start with the vocabulary of the language with which a user approaches the knowledge organization system.
An English language index to a classification scheme that uses a decimal numeric notation serves an obvious need. It is, however, only one case of a broader class of mappings in the multiplicity of vocabularies which permeate information services (Buckland, 1999). There is likely to be a need for indexes in French or other natural languages to the same classification. Also, knowledge organization systems based on natural language, such as lists of subject headings and thesauri, are also likely to need indexes because these controlled vocabularies are invariably more or less stylized. It cannot be assumed that the provision of USE cross-references will meet all users' needs. Another category is the creation of indexes to knowledge organization systems not in natural language vocabulary but in the "vocabulary" of another knowledge organization system, such a mapping between the U.S. Patent & Trademark Office's Patent Classification and the International Patent Classification of the World Intellectual Property Office.
Unfortunately, such indexes (or mappings or "crosswalks") are expensive and time-consuming to create, and they are liable to become obsolescent as terminology evolves and knowledge organization systems are revised. Creating such mappings requires a large investment of effort by people highly skilled in knowledge organization and in the domain concerned. The development of the Unified Medical Language System by the U.S. National Library of Medicine is an outstanding example.
A team at the School of Information Management and Systems, University of California, Berkeley, has been developing an alternative approach to the creation of indexes to knowledge organization systems, and, more generally, to mappings between pairs of vocabularies. We have been using statistical association techniques to establish relationships between terms in one vocabulary and the terms in another. In addition, natural language processing software for identifying adjective-noun phrases enables us to map from phrases of natural language as well as individual words. This approach is seen as complementary to hand-crafted mappings, not a substitute. Indexes based on statistical association can be created in a matter of hours, not years, and so can serve as an interim solution and as a prompting service for the creation of hand-crafted mappings (Buckland & others, 1999).
2. The Methodology of "Classification Clustering"
Our technique of creating a ranked list of probably relevant terms in the target metadata vocabulary from any given searcher input was developed under the name "Classification clustering" by Ray Larson and used by him to the interface for the CHESHIRE prototype retrieval system which allowed a searcher to express a query in free-form English. CHESHIRE would respond with a ranked list of Library of Congress Classification numbers likely to match that query (Larson, 1991; 1992). He used probabilistic interpretation of vector-spaced retrieval, extended by William S. Cooper's Staged Logistic Regression method (Gey 1994). A two-stage lexical collocation process is used. The first stage is creation of an Entry Vocabulary Module, a "dictionary" of associations between the lexical items found in the titles, authors, and/or abstracts and the metadata vocabulary (i.e. the category codes, classification numbers, or thesaural terms assigned), using a likelihood ratio statistic as a measure of association. In the second stage, deployment, the dictionary is used to predict which of the metadata terms best represent the topic represented by the searcher's terms (Plaunt & Norgard, 1998).
In Larson's original method, Entry Vocabulary Modules were derived from the frequency of occurrence of single terms. More recently natural language parsing software has been used to identify noun phrases and to use these phrases instead of the individual words within them (Kim & Norgard 1998).
The project "Search Support for Searching Unfamiliar Metadata" at Berkeley has been expanding the use of this technique and generating prototype "Entry Vocabulary Modules" from words and phrases of English (or other natural languages) to each of a variety of knowledge organization systems, primarily the LC Classification, BIOSIS concept codes, the INSPEC Thesaurus, the Standard Industrial Classification, and the U.S. and International Patent Classifications. (For a convenient introduction to this work see Buckland and others (1999; also Search, 2000)).
As an example, an inexperienced library user of the Berkeley science libraries may well not know where to look for books on "Alien life forms." Entering that query into our index to the Library of Congress Classification scheme, as implemented for the Berkeley science libraries will lead to QB 54, which is associated with LC Subject Headings "Life on other planets" and "Interstellar communication," and QH 325, associated with "Life Origin" and "Life on other planets."
3. Subdomains and Specialized Vocabularies.
Every group tends to evolve its own distinctive usage of language, its own allusions, its own specialized jargon. This is more or less true of all communities. This phenomenon is of special significance for knowledge organization systems concerned with technical fields. Each community of practice has its specialized terminology for its particular concerns as well as tendencies to develop distinctive usage of words in wider use.
Bibliographies and their knowledge organization system commonly cover broad topical areas. For a specialized domain, an index derived from the specialized use of language within that domain would appear to be advantageous, but likely to be in conflict with a general-purpose index for all domains. With hand-crafted indexes, one can hardly afford to provide both general and specialized indexes.
The tension between catering to the focused needs of a specialist group and providing universal access to the general public is not new. What is new is that the use of statistical association techniques allows the rapid and inexpensive generation of multiple, specialized indexes to the same corpus. We have been exploring the idea of multiple indexes to the same knowledge organization system, each intended to serve the needs of a different (sub)domain (Subdomain, 2000). What difference would specialized indexes make?
4. Indexes to Subdomains.
To examine this question, four different indexes were made to the INSPEC Thesaurus. One was based on a random sample of records from the entire database and three were based on records relating to specialized sub-domains: Biotechnology, Information Science, and Water. These indexes are openly web-accessible at Search (2000), although for licensing reasons, only searchers with a Berkeley IP address can, after using the index, extend the search to the University of California's INSPEC database.
In practice, bibliographic databases with a broad scope include literatures concerned with smaller, more specialized topics which constitute specialized domains of discourse. For any particular, specialized inquiry a searcher is unlikely to be equally interested in all parts of the database in broad bibliographic database, but rather in one particular subdomain within it. In this case, using a single, general-purpose mapping (index), based on the database as a whole, from, say, English, to the knowledge organization system, may be less effective (of lower "Precision") than using a specialized mapping based only on discourse in the sub-domain of interest. If so, then it could be advantageous to have multiple, specialized indexes to the same corpus. We have, therefore, started to experiment with specialized indexes to subdomains.
INSPEC database is an abstracting service covering articles in over 4,000 scholarly journals, conference proceedings, books, reports, and dissertations in physics, electrical engineering and electronics, computers and control, and information technology. We have used the 1995-1999 INSPEC dataset mounted by the University of California's California Digital Library in association with the MELVYL tm online catalog. We created a "General" entry vocabulary index for the database as a whole, based on a random sample of 152,646 INSPEC records collected in June 1999. We also created three subdomain entry vocabulary indexes:
-- "Biotechnology," using the 13,386 records that were retrieved with a search on October 27, 1997, of all records in all journals in which the journal's title contained a word beginning with the letters "bio" (F JO BIO);
-- "Information Science," using 9,549 records that were retrieved in a search in August 1999 for all records in all journals listed in the Science Citation Index Journal Citation Reports subject category "Information Science and Library Science;" and
-- "Water," using 9,613 records that were retrieved in a search in June 1999 for all records in all journals listed in the Science Citation Index Journal Citation Reports subject category "Water Resources."
These entry vocabulary indexes are openly available for searching at http://sims.berkeley.edu/research/metadata/oasis.html
It became clear, immediately, that for any given query the specialized relative indexes often indicated different INSPEC Thesaural terms and, as a result, to different retrieval results. For example, the query "water":
-- Using the BIO sub-domain index indicated the following INSPEC Thesaurus terms: Water (9,319 records); Biomechanics; Physiological models; Neurophysiology; Cellular effects of radiation; Cardiology; Muscle; Blood; Bone; and Biomedical ultrasonics.
-- Using the INFORMATION SCIENCE subdomain index: Agriculture (1,460 records); Natural resources; Forecasting theory; Operations research; Erosion; Geomorphology; Rain; Soil; Public utilities; and Town and country planning.
-- Using the WATER subdomain index: Fission reactor safety (2,914 records); Fission reactor fuel; Polymers; Organic insulating materials; Water supply; Cable insulation; Insulation testing; Insulating oils; Liquid structure; and Fission reactor operation.
It will be noted that in this case there is no duplication at all in these sets of suggested thesaural terms, but other queries, e.g. for "chaos," did lead to the same thesaural terms and, therefore, to identical retrieved sets. We decided to examine not only the variation between the indexes but also, based on an insight by Barbara Norgard, whether this variation might vary with the extent to which words had multiple meanings.
5. Experiment I: How Different are Subdomain Indexes?
We selected a sample of 600 words at random from each of the four samples used to create the four entry vocabulary indexes. These 2,400 words were then checked against Wordnet 1.6, an online thesaurus which enumerates the different meanings of each word (WordNet, 2000). For each word the number of meanings was noted. Words not found in WordNet were assumed to have a single meaning on the grounds that a word not in WordNet was likely to be a new or rare word. A stratified sample was then created for each of the indexes, each composed 100 words with a single meaning, another 100 with two meanings, and other 100 each for words with three, four, five, and six meanings.
The sample drawn from the General Index was then used as a query and searched against both the General Index and the three Subdomain Indexes and the resulting top-ranked Thesaural terms compared. In nearly half the cases one or more Subdomain indexes did not yield any Thesaural terms. The reason being that the query word had not been present in the training set used to create index. These words were discarded. For the remaining 357 words, for which all three subdomain indexes did yield Thesaural terms, the number that differed from the General index were counted. Thus, when all three Subdomain indexes yielded the same Thesaural term as the General index, the difference was zero, where one, two or all three were different the count was 1, 2, and 3 respectively.
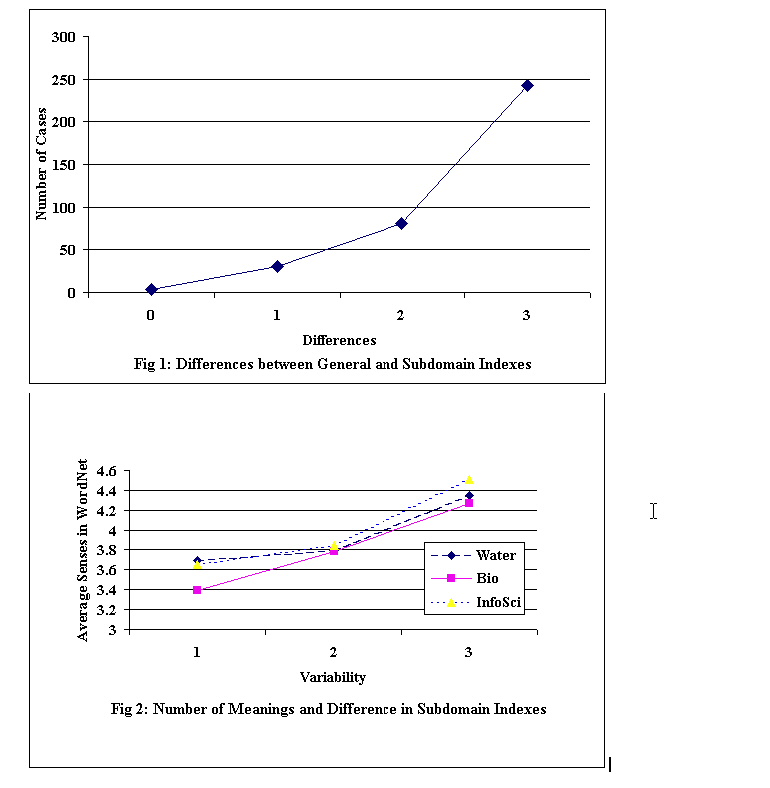
The difference was very marked. In two-thirds of the cases (242 out of 357, 68%) the three subdomain indexes all yielded a different Thesaural term than the General index, for 81 queries (23%) two yielded different Thesaural terms, for 30 queries (8%) only one yielded a different Thesaural term, and in just 4 cases (1%) was there complete agreement. These results are shown in Figure 1. There was also substantial differences between the Subdomain indexes.
6. Experiment II: Multiple Meanings and Index Variability.
For each of the words in our samples we had a "difference value" (as explained above) and also a count of the number of meanings based on WordNet. It was possible, therefore, to look for a relationship between these values. The procedure in Experiment I was repeated, but using the three samples of words drawn from the training sets used to create the three Subdomain indexes and each of the words in these three samples was searched against all three Subdomain indexes, resulting is a "variability" on a scale from 1 to 3 resulted according to whether one, two, or three different Thesaural terms resulted. These variability scores were then compared with the number of meanings for each word. We found a strong, consistent, positive correlation as shown in Figure 2 where the average number of meanings for words with a variability of 1, 2, and 3 respectively is shown for each of the three samples. For the Bio sample, the average numbers of meanings was 3.40, 3.78, and 4.26 respectively. For the Information science sample they were 3.65, 3.85, and 4.51 respectively and for the Water sample 3.69, 3.79, and 4.35. The more meanings a word has, the more likely that will lead to different Thesaural terms in different Subdomain indexes.
7. Discussion
This work raises a variety of practical and theoretical issues, including the problem of identifying subdomains, since the boundaries between them may not be distinct.
(i) These are preliminary, exploratory results. Some of the differences found may have methodological causes. In particular, the training sets drawn from sub-domains tend to be relatively small and, as a result, less reliable and less complete. More work is needed to ascertain how the results have been influenced by methodological factors. In particular, we intend to look at more than just the first ranked thesaural term and also at the consequences for retrieval. Different thesaural terms may nevertheless lead to similar or overlapping retrieved sets.
(ii) What is the nature of subdomain indexes derived from statistical association? They resemble Boolean modifiers for context. It is reasonable that a query in the form FIND SUBJECT WATER AND CONTEXT BIOLOGY would lead to Biomechanics, and Permeability of Membranes; that FIND SUBJECT WATER AND CONTEXT INFORMATION SCIENCE would lead to Rain and Forecasting; and that but FIND SUBJECT WATER AND CONTEXT NUCLEAR ENGINEERING should lead to Cooling Systems and Fission Reactor Safety.
(iii) The indexes we have used are based on association. The relationship is that the word of the query is statistically associated with a particular value in the knowledge organization system. This is different from conventional practice in which vocabulary relationships are ordinarily based on three semantic relationships: synonomy (USE); hierarchy (NARROWER TERM; BROADER TERM; and, sparingly, undefined ("RELATED TERM"). This difference can explain why indexes created by statistical association lead to words that are not semantically related, but may be functionally related. Consider the following mapping: "If you are interested in WATER, then try searching under PERMEABILITY OF MEMBRANES." This advice reflects a functional relationship between water and membranes, rather than a semantic one. It could be very beneficial for a biologist, but not for a hydrologist and not for an engineer interested in nuclear power station cooling systems.
(iv) The difference between semantic and functional relationships opens up the question of what relationships would serve users best in providing access to organized knowledge. The relationships generated by statistical association within bibliographic corpora are based on literary warrant. They can be interpreted as saying, "If you want A, try term B." Surely this is just what one would hope for from a , human or mechanical intermediary.
The traditional emphasis on two semantic relationships (synonymy and hierarchy) have the virtue that they can be created by hand, but, perhaps, they should be seen as incomplete, as just two kinds of steps towards a more complex goal.
(v) We have spoken of domains and subdomains. Major questions arise concerning how to define, or even recognize, a domain and at what level of granularity. Domains have subdomains within them and it is unrealistic to expect tidy boundaries.
(vi) Our findings are only preliminary and exploratory. But on our limited experience, the impact of subdomain indexes to knowledge organization systems is so striking as to call into question the traditional practice of providing only one single, general index. And, if subdomains are desired, only associative, statistical techniques are likely to be affordable.
Acknowledgment
The work reported was supported by the U.S. Defense Advanced Research Projects Agency contract "Search Support for Unfamiliar Metadata Vocabularies" DARPA N66001-97-C-8541; AO# F477 July 1997 - June 2000) and by a National Leadership Grants for Libraries Research & Demonstration grant "Seamless Searching of Numeric and Textual Resources" from the U.S. Institute for Museum and Library Services (Oct 1999 - Sept 2001). For both the Principal Investigators are Michael Buckland, Fredric Gey, and Ray Larson.
References
Buckland, Michael. (1999). Vocabulary as a Central Concept in Library and Information Science. In: Digital Libraries: Interdisciplinary Concepts, Challenges, and Opportunities. Proceedings of the Third International Conference on Conceptions of Library and Information Science (CoLIS3), Dubrovnik, Croatia, 23-26 May 1999. Ed. by T. Arpanac et al. Zagreb: Lokve, pp 3-12. ISBN 953-6003-37-6. http://www.sims.berkeley.edu/~buckland/colisvoc.htm
Buckland, Michael & others. (1999). Mapping Entry Vocabulary to Unfamiliar Metadata Vocabularies. D-Lib Magazine 5, no. 1 (Jan 1999). http://www.dlib.org/dlib/january99/buckland/01buckland.html
Gey, F. (1994). Inferring Probability of Relevance Using the Method of Logistic Regression. In: Proceedings of SIGIR94, the 17th annual ACM conference on Research and Development in Information Retrieval, Dublin, Ireland, July 4-6, 1994. Association for Computing Machinery. pp. 222-231.
Kim, Youngin and Norgard, Barbara. (1998). Adding Natural Language Processing Techniques to the Entry Vocabulary Module Building Process. Technical report. http://www.sims.berkeley.edu/research/metadata/nlptech.html
Larson, Ray R. (1991). Classification Clustering, Probabilistic Information Retrieval and the Online Catalog. Library Quarterly, vol. 61, no. 2 (April), 1991, pp. 133-173.
Larson, Ray R. (1992). Experiments in Automatic Library of Congress Classification. Journal of the American Society for Information Science, v. 43 no. 2 (March 1992), pp. 130-148.
Search Support for Unfamiliar Metadata.. (2000). [Project website]. http://sims.berkeley.edu/research/metadata/
Subdomain Vocabularies. (2000). [Website]. http://sims.berkeley.edu/research/metadata/sub.html
WordNet 1.6 (2000) http://www.cogsci.princeton.edu/~wn/obtain/ Downloaded February 18, 2000.